-
Latin America
-
Central & Eastern Europe
-
Middle East & Africa
-
Asia
Словарь современных терминов Data Science и машинного обучения

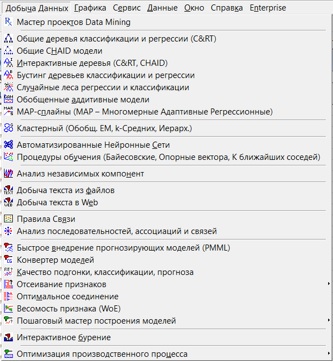
Statistica — универсальная система анализа данных и дейта сайнс, содержащая как классические, так и современные методы анализа данных, доступные пользователям в удобном диалоговом режиме.
Statistica содержит более 10 000 аналитических и статистических процедур, включая машинное обучение и нейронные сети, и имеет более миллиона пользователей во всем мире. Коннектор Statistica с R позволяет эффективно использовать библиотеки открытого программного обеспечения.
![]()
Apache Hadoop — платформа с открытым исходным кодом для обработки большого объема данных в кластерной среде. Он использует простую модель программирования MapReduce для надежных, масштабируемых и распределенных вычислений. Хранилище и вычисления распределены в этой структуре. Apache Hadoop обеспечила революцию больших данных, по крайней мере, с точки зрения программного обеспечения.
![]()
Apache Spark — мощный движок обработки исходного кода, основанный на скорости, простоте использования и сложной аналитике с API-интерфейсами в Java, Scala, Python, R и SQL. Spark запускает программы до 100 раз быстрее, чем Apache Hadoop MapReduce в памяти, или в 10 раз быстрее на диске. Может использоваться для создания приложений данных в виде библиотеки или для интерактивного анализа данных ad hoc.
Spark предоставляет стек библиотек, включая SQL, DataFrames и Datasets, MLlib для машинного обучения, GraphX для обработки графов и Spark Streaming. Вы можете объединить эти библиотеки в одном приложении. Кроме того, Spark работает на ноутбуке, Apache Hadoop, Apache Mesos, автономно или в облаке. Он может обращаться к различным источникам данных, включая HDFS, Apache Cassandra, Apache HBase и S3.

JavaScript — язык сценариев (не имеющий отношения к Java), первоначально разработанный в середине 1990-х годов для встраивания логики в веб-страницы, но впоследствии зарекомендовал себя как универсальный язык разработки. JavaScript по-прежнему очень популярен для встраивания логики в веб-страницы, так как доступно множество библиотек для улучшения работы и визуального представления этих страниц.
C-статистика — оценивает площадь под ROC-кривой и может использоваться для оценки качества и сравнения диагностических тестов.
CART — Classification and regression trees — деревья классификации и регрессии. Алгоритм Classification and Regression Tree разработан Leo Breiman, Jerry Friedman, Charles Stone и Richard Olshen. Алгоритм строит бинарные деревья, имеющие двух потомков в каждом узле дерева. На каждом шаге построения дерева правило, формируемое в узле, делит заданную обучающую выборку на две части – часть, в которой выполняется правило (левый потомок) и часть, в которой правило не выполняется (правый потомок). Для выбора оптимального правила разбиения используется функция оценки качества разбиения. Функция оценки качества разбиения основана на идее уменьшения неопределенности в узле. Дерево решений с непрерывными выходными значениями называется деревом регрессии, деревья классификации выводят конкретные категориальные значения. В дереве имеется один особый узел, известный как корневой. Это основа дерева, от которой можно перейти по дереву к любому узлу. Ключевым моментом является иерархия разбиений. В результате последовательности проверок организуется процесс разбиения данных на непересекающиеся подмножества. Каждый листовой узел соответствует небольшой, но исключительной (неповторяющейся) части исходного множества.
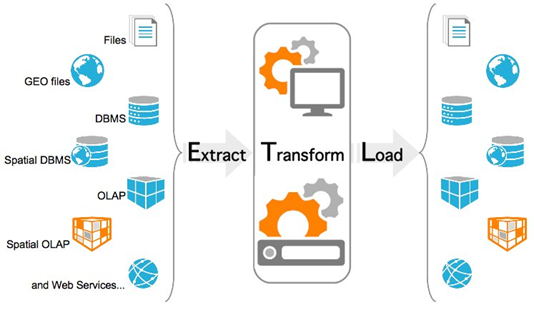
ETL (Extract, Transform, Load - Извлечение, Преобразование, Загрузка) — процесс извлечения данных из исходных систем, таких как транзакционные базы данных, и помещения их в хранилища данных. Если вы знакомы с онлайн-транзакционной обработкой (OLTP) и онлайн-аналитической обработкой (OLAP), ETL можно рассматривать как мост между этими двумя системными типами. Под ETL часто подразумевают как отдельную систему класса BI (или её компоненту), так и этап в анализе данных. Необходимость в ETL обусловлена разнообразием источников, в которых хранятся данные. Источники могут сильно отличаться как платформами, так и архитектурой: структура таблиц, разные справочники, различная детализация данных и др. Например, на производстве потоковые данные могут хранится в системе PI, а результаты прецизионных лабораторных замеров в системе LIMS. Причем разрешение данных в PI системе может быть доли секунды, а в LIMS – часы и даже сутки. Аналогично, может возникнуть задача компоновки данных из ERP, CRM, систем веб-аналитики и т.д. Этапы ETL процесса можно представить следующим образом:
- Загрузка данных из источников.
- Поиск, очистка/исправление ошибок в данных.
- Приведение к единим метрикам/размерностям/справочникам.
- Агрегация до необходимой детализации.
- Выгрузка в целевую систему/хранилище.
F-распределение Фишера — вытянутое вправо непрерывное распределение, характеризующееся степенями свободы числителя и знаменателя. Используется в дисперсионном анализе.
Keras — открытая нейросетевая библиотека, написанная на языке Python. Представляет собой надстройку над фреймворками Deeplearning4j, TensorFlow, Theano. Ключевая идея Keras: дать возможность переходить от идеи к результату в глубоком обучении с наименьшей возможной задержкой. Согласно исходной концепции Keras, является скорее интерфейсом, чем сквозной системой машинного обучения.
N факториал — для положительного целого n, обозначение n! используется в таком виде:
n х (n-1) х (n-2) … х 2 х 1.
Например 5!=5х4х3х2х1=120.
0! определяется как 1.
P-значение — вероятность получения наших результатов или чего-либо большего, если нулевая гипотеза верна; уровень значимости.
PageRank — алгоритм, который определяет важность чего-либо, обычно ранжирует его в списке результатов поиска. PageRank работает путем подсчёта количества и качества ссылок на страницу, чтобы определить приблизительную оценку важности веб-сайта. Основное предположение заключается в том, что более важные веб-сайты могут получать больше ссылок с других веб-сайтов. PageRank назван не по названию страниц, которые он занимает, а по имени своего изобретателя, соучредителя и генерального директора Google Ларри Пейджа.
Pandas — библиотека Python для манипулирования данными, популярная среди исследователей данных.
Python — язык программирования, доступный с 1994 года, популярный среди исследователей, занимающихся наукой о данных. Python отличается простотой использования среди новичков и большой мощностью при использовании опытными пользователями, особенно когда используются преимущества специализированных библиотек, таких как библиотеки, предназначенные для машинного обучения и генерации графиков.
R2 — коэффициент детерминации, доля общей дисперсии зависимой переменной в регрессионном анализе, которая объясняется моделью.
Structures Query Language (SQL) — язык программирования, разработанный для управления и извлечения данных из системы реляционных баз данных.
t-распределение — также называется распределением Стьюдента. Непрерывное распределение, чья форма подобна нормальному распределению и которое характеризуется своей степенью свободы. Используется для проверки гипотез о средних значениях выборки.
TensorFlow™ — программная библиотека с открытым исходным кодом для высокопроизводительных численных расчетов. Гибкая архитектура позволяет развертывать вычисления на различных платформах (процессорах, графических процессорах, TPU), от настольных компьютеров до кластеров серверов, мобильных и периферийных устройств. Обеспечивает поддержку машинного обучения и глубокого обучения, гибкое ядро для численных вычислений используется во многих других научных областях.
Абсолютное значение — неотрицательное число, обозначаемое |x| и определяемое как:
если x < 0, то |x| = -x,
если x ≥ 0, то |x| = x.
Алгоритм — упорядоченный набор действий (операций, процедур), которые приводят к достижению заранее поставленной цели. Например, алгоритм Евклида указывает, как найти наибольший общий делитель (НОД) двух натуральных чисел a и b.
Пусть a > b.
Шаг 1. a = b*q1 + r1
Если r1 = 0, то НОД (a, b) = b
Если r1 > 1, то шаг 2.
Шаг 2. b = r1*q2 + r2
Если r2 = 0, то НОД (a, b) = r1
Если r2 > 0, то шаг 3 и тд.
Так как b > r1 > r2 >…, то процесс заканчивается при любых заданных a и b за конечное число шагов и наибольший общий делитель будет найден.
Пусть требуется решить систему двух уравнений первой степени с двумя неизвестными x, y:
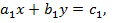
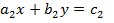
Алгоритм решения этой системы дается формулами
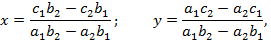
в которых полностью выражен как состав действий, так и порядок их выполнения.
В приведенных формулах предусмотрена одна и та же цепочка действий для всех задач данного типа. Алгоритм работает при любых коэффициентах 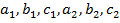 в предположении, что знаменатели приведенных выражений не обращаются в 0.
в предположении, что знаменатели приведенных выражений не обращаются в 0.
В противоположность классическому алгоритму, эвристические алгоритмы — алгоритмы решения задачи, правильность которых не доказана для всех случаев, но про которые известно, что они дают достаточно хорошее решение в большинстве случаев. В дейта сайнс интенсивно используются разнообразные алгоритмы, в частности алгоритм градиентного спуска нахождения локального минимума функции потерь с помощью движения вдоль градиента.
Алгоритм градиентного бустинга (boosting — улучшение, xgboost) — процедура последовательного построения композиции алгоритмов машинного обучения с целью улучшения качества классификации или предсказательной силы модели.
Алгоритм обратного распространения ошибки (backpropagation) — применяется для обучения многослойных персептронов. Ключевая идея состоит в том, чтобы вычислить градиент функции потерь, необходимый для корректировки весов, которые необходимо использовать в сети. Вначале веса нейронов выбираются случайным образом, далее сеть обучается на входных наборах обучающей выборки. Выход нейрона зависит от взвешенной суммы его входов, который далее через передаточную функцию передается на другие нейроны и достигает последнего слоя. Функция потерь зависит от параметров сети и интуитивно представляет собой некоторую «стоимость», связанную с этими значениями. Фактически функция потерь задает меру несоответствия между ожидаемым сигналом на выходе сети и значением, которое наблюдается на обучающей выборки. Вначале ошибка вычисляется на последнем выходном слое, далее она подается на нейроны предыдущего слоя и тд. Корректировка весов производится с помощью метода градиентного спуска. Обычно функция потерь является квадратичной, функции активации нейронов дифференцируемые функции, что позволяет применять градиентный спуск.
Альтернативная гипотеза, альтернатива — гипотеза относительно интересующего нас эффекта, которая противоречит нулевой гипотезе и верна, если нулевая гипотеза ложная.
Альфа зиро (Alpha Zero) — алгоритм игры в шахматы, основанный на нейронных сетях и самообучении.
Апостериорная вероятность — индивидуальное доверие, основанное на априорной вероятности и новой информации (например, результат критериальной проверки), в то, что событие произойдёт.
Апостериорные сравнения — делаются для корректировки значения P, когда проводятся множественные (многократные) сравнения гипотез, например поправка Бонферрони или более мощная современная поправка Холма (1979).
Априорная, доопытная вероятность — априорная вероятность, оценённая до появления результата диагностического теста.
Арифметическое среднее — мера положения, полученная делением суммы значений переменной по наблюдениям на число слагаемых, часто называемая просто средним.
Асимметричное распределение — асимметричное распределение данных имеет длинный хвост справа с несколькими высокими значениями (положительно скошенное) или длинный хвост слева с несколькими низкими значениями (отрицательно скошенное).
База данных (Database). Для данных необходим особый способ хранения и обработки, чтобы они могли трансформироваться в информацию и далее использоваться для каких-либо полезных выводов. Базы данных обычно содержат совокупности записей данных или файлов, таких как последовательность производственных действий, транзакции, каталоги продуктов, запасы, профили клиентов и т.д. Данные обновляются, расширяются и удаляются по мере добавления новой информации. Данные организованы в строки, столбцы, таблицы, которые индексируются, чтобы упростить поиск необходимой информации. Одна из задач специалиста в дейта сайнс - уметь работать с системами управления базами данных, выгружать данные из различных баз данных для дальнейшего их анализа.
Базы данных XML позволяют хранить данные в формате XML. Базы данных XML часто связаны с документно-ориентированными базами данных. Данные, хранящиеся в базе данных XML, можно запрашивать, экспортировать в любой необходимый формат.
Байесовский метод вывода — вывод на основе теоремы Байеса, использует не только текущую информацию, но и прежнее суждение о гипотезе для оценки апостериорной вероятности, оценивающей уровень доверия к гипотезе после наблюдаемых событий.
Байесовская сеть — это вероятностная графическая модель (тип статистической модели), которая представляет набор переменных и их условных зависимостей с помощью направленного ациклического графа. Например, байесовская сеть может представлять вероятностные отношения между признаками клиента и его покупками. С учетом различных признаков сеть можно использовать для расчета вероятности приобретения тех или иных групп товаров, отклика на рекламу и т. д. Эффективные алгоритмы могут выполнять вывод и обучение в байесовских сетях. Байесовские сети, моделирующие последовательности переменных (например, речевые сигналы или белковые последовательности), называются динамическими байесовскими сетями. Обобщения байесовских сетей, которые могут представлять и решать задачи решения в условиях неопределенности, называются диаграммами влияния, основаны на теореме Байеса.
Бернулли испытание — эксперимент только с двумя возможными исходами, например, выпадение герба или решки при бросании монеты. Вероятность выпадения герба полагается равной p, вероятность выпадения решки q.
0 < p, q < 1, p + q = 1.
Для симметричной монеты имеем следующие значения параметров распределения Бернулли: p = q = ½.
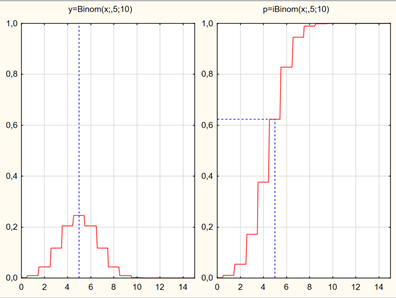
Случайная величина, равная числу успехов в N независимых испытаниях Бернулли, имеет биномиальное распределение, которое интенсивно используется в различных областях, включая телекоммуникации, страхование, промышленность (карты контроля качества).
Бета-уровень (β-уровень) — вероятность ошибочного принятия нулевой гипотезы, когда в действительности верна альтернатива. В клинических исследованиях значение β-уровня обычно устанавливается равным 0,2 или 0,1. Величина (1- β) – статистическая мощность теста, в клинических исследованиях обычно 0,8 вероятность выявления разницы между группами при условии, что она действительно существует. Если выборки малы, то статистическая мощность может быть низкой. Для больших выборок статистические тесты имеют большую статистическую мощность, это означает, что истинные различия между группами выявляются с большей вероятностью.
Бизнес-аналитика (Business Intelligence). Бизнес-аналитика включает в себя стратегии, технологии и информационные системы, стремясь улучшить принятие решений на основе прошлых результатов с использованием отчетов, OLAP, панелей мониторинга, систем показателей, таблиц, визуализация данных, предиктивных моделей, построенных как с помощью классических статистических методов, так и с помощью дейта майнинга и машинного обучения.

Бимодальное распределение — распределение, имеющее две моды, два максимума плотности распределения. Обычно свидетельствует о неоднородности данных.
Бинарная переменная — качественная переменная с двумя категориями, также называется дихотомической переменной.
Бинарные данные — данные, выражаемые только двумя альтернативными значениями, например, да, нет, при ответе респондентов.
Биномиальная теорема — даёт разложение (x + y)n, где n — любое натуральное число в виде:
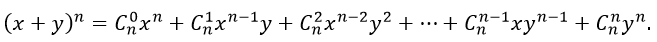
где 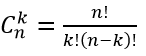 число сочетаний из n по k.
число сочетаний из n по k.
Например, (x + y)2 = x2 + 2xy + y2
(x + y)3 = x3 + 3x2y + 3xy2 + y3
Биномиальное распределение — распределение количества «успехов» в последовательности из n независимых случайных экспериментов, таких что вероятность «успеха» в каждом из них равна p.
Рассмотрим независимые случайные величины 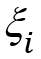 , имеющие распределение Бернулли: , принимает значение 1 или "успех" с вероятностью p; значение 0 или "неудача" с вероятностью q = 1 - p. Вероятность получить k успехов в серии n независимых испытаний равна:
, имеющие распределение Бернулли: , принимает значение 1 или "успех" с вероятностью p; значение 0 или "неудача" с вероятностью q = 1 - p. Вероятность получить k успехов в серии n независимых испытаний равна:
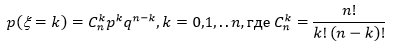
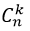 - число сочетаний из n по k;
- число сочетаний из n по k;
p - вероятность успеха в каждом испытании;
q - величина, равная 1-p;
n - число независимых испытаний.
Пример: вероятность выпадения двух гербов при двукратном бросании симметричной монеты равна ¼. Для симметричной (правильной) монеты выпадения герба или решки равновероятно: q = p = ½ 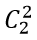 = 1, следовательно, вероятность выпадения двух гербов P (
= 1, следовательно, вероятность выпадения двух гербов P ( =2) =¼.
=2) =¼.
Блок, группа — однородная группа экспериментальных единиц, которые имеют подобные характеристики, также называется «страта».
Большие данные (Big Data) — включает в себя стратегии, технологии и информационные системы, направленные на получение, обработку, хранение, анализ и визуализацию сложных структурированных и неструктурированных наборов данных с помощью пакетной обработки, потоковой обраб